
剪辑:剪辑部云开体育
只用4500好意思元资本,就能收效复现DeepSeek?就在刚刚,UC伯克利团队只用约略的RL微调,就训出了DeepScaleR-1.5B-Preview,15亿参数模子胜利吊打o1-preview,轰动业内。
强化学习迎来要紧冲破!
近日,来自UC伯克利的参谋团队基于Deepseek-R1-Distilled-Qwen-1.5B,通过约略的强化学习(RL)微调,得到了全新的DeepScaleR-1.5B-Preview。
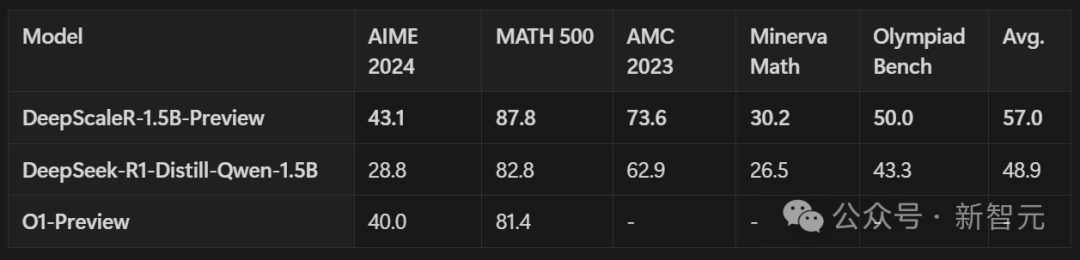
在AIME2024基准中,模子的Pass@1准确率达高达43.1% ——不仅比基础模子提高了14.3%,并且在惟有1.5B参数的情况下超越了OpenAI o1-preview!
当今,参谋团队已开源数据集、代码和考验日记。
只用不到5000好意思元的预算,团队就复现了DeepSeek的收效。至此,开源又赢下一局。
网友们奖饰:当机器学习和数学再会,即是超强组合的出生!
考验隐私简版:先短后长
1.5B模子,通过RL考验,就能超越o1-preview,进行数学推理?
简而言之,团队此次的考验计谋即是四个字——先短后长。

第一步,参谋东说念主员会考验模来型进行短念念考。他们使用DeepSeek的GRPO要领,设定了8k的盘曲文长度来考验模子,以荧惑高效念念考。
经过1000步考验后,模子的token使用量减少了3倍,并比基础模子晋升了5%。
接下来,模子被考验进行长念念考。强化学习考验彭胀到16K和24K token,以惩办更具挑战性、以前未惩办的问题。
跟着反馈长度增多,平均奖励也随之提高,24K的魅力,就让模子最终超越了o1-preview!
DeepScaleR-1.5B-Preview
最近,Deepseek-R1开源发布,对推理模子技巧普及来说,是个紧要冲破。不外,它具体的考验要领、超参数还有底层系统,齐还没公开。
在彭胀强化学习的时候,最大的穷苦之一即是狡计资本太高。
就拿DeepSeek-R1的执行来说,要想透彻复现,盘曲文长度得达到32K以上,考验大约8000步,就算是惟有1.5B参数的模子,起码齐得花70,000 GPU小时。
何如讹诈强化学习,把微型模子酿成超好坏的推理模子呢?
为了惩办这个问题,参谋东说念主员用了学问蒸馏模子,还改进性地引入了强化学习迭代延迟要领。
团队推出了DeepScaleR-1.5B-Preview模子,它经过4万个高质料数学问题的考验,考验一共用了3800个A100 GPU小时。
最终,资本只需约4500好意思元,省了18.42倍!同期模子的性能还在几个竞赛级数学基准中,杰出了o1-preview。
参谋标明,用强化学习设备定制化的推理模子,既能大限制进行,还能限度资本,性价比超高!
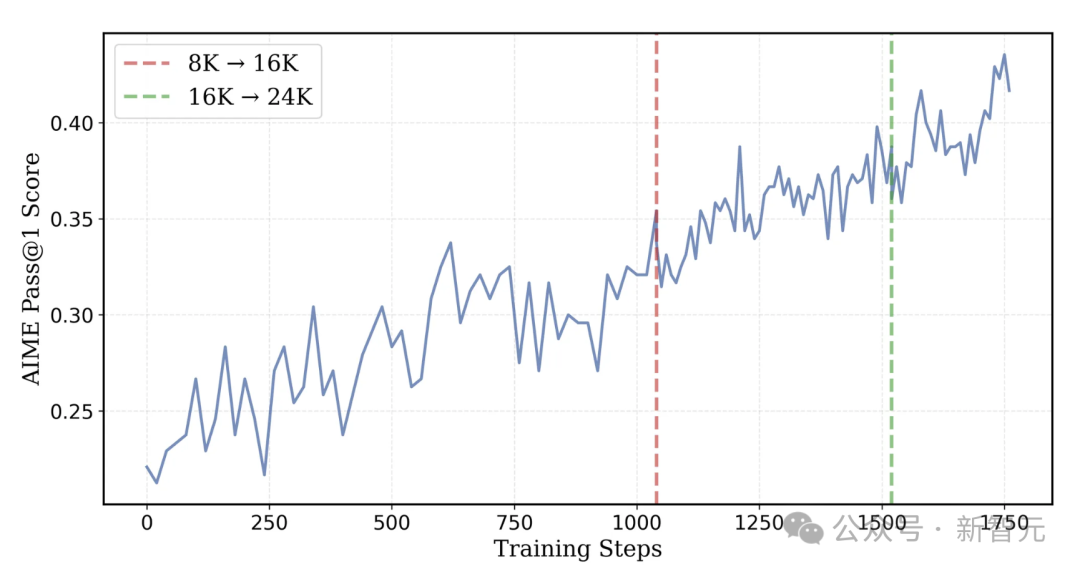
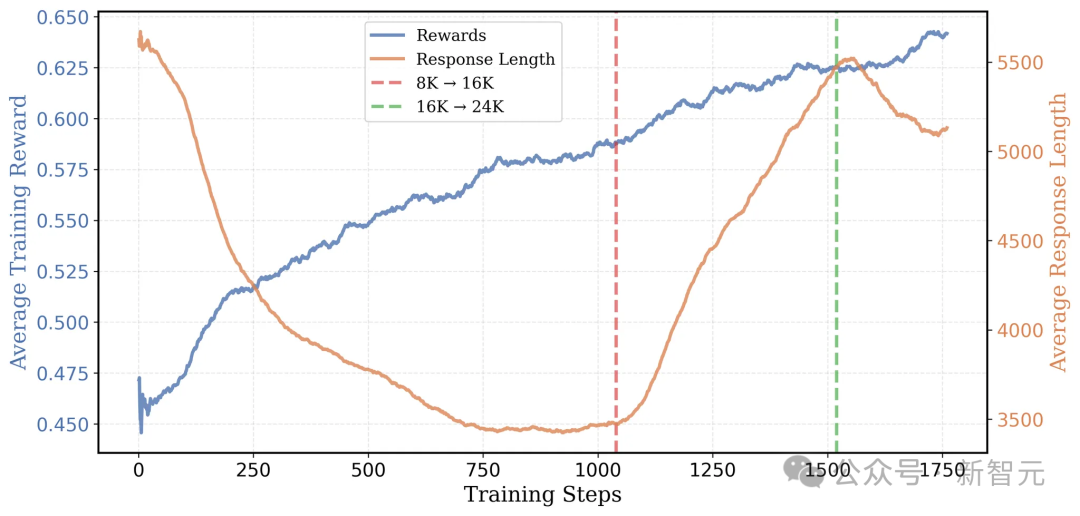
AIME 2024测试集Pass@1准确率随考验程度而变:考验至第1040步,盘曲文长度扩至16K token;到第1520步,盘曲文长度增至24K token
技巧决议
数据集构建
在考验数据集方面,参谋东说念主员网络了1984至2023年的好意思国国外数学邀请赛(AIME)、2023年之前的好意思国数学竞赛(AMC),以及来自Omni-MATH和Still数据集的列国及国外数学竞赛题目。
数据处理过程包含三个中枢要领:
谜底索取:关于AMC和AIME等数据集,使用gemini-1.5-pro-002模子从AoPS官方解答中索取谜底。
重复问题计帐:基于RAG,并劝诱sentence-transformers/all-MiniLM-L6-v2的词向量镶嵌来遗弃重复问题。同期,对考验集和测试集进行重复检测,以驻防数据浑浊。
弗成评分题目过滤:数据集(如Omni-MATH)中的部分问题,无法通过sympy数学象征狡计库评估(得靠LLM判断)。这不仅会缩小考验速率,还会引入不踏实的奖励信号,因此需要增多出奇的过滤要领,来剔除无法自动评分的问题。
在经夙昔重和过滤之后,就得到了约4万个特有的问题-谜底对四肢考验数据集。
奖励函数联想
按Deepseek-R1的教会,用收尾奖励模子(ORM)而不是过程奖励模子(PRM),来幸免模子通过顺风转舵得到奖励。
奖励函数复返值如下:
复返「1」:如果LLM的谜底,既能通过LaTeX语法搜检,又能通过Sympy数学考据,就给它奖励。
复返「0」:若是LLM的谜底是错的,或者神色不合,比如少了和象征,那就不给奖励。
迭代增多盘曲文长度:从短到长的念念维彭胀
推理任务由于会生成比法度任务更长的输出,狡计支出较大,这会同期缩小轨迹采样(Trajectory Sampling)和计谋梯度(Policy Gradient)更新的速率。
与此同期,盘曲文窗口大小翻倍,则会导致考验狡计量至少增多2倍。
这种情况产生了一个根人性的量度弃取:较长的盘曲文能为模子提供更饱胀的念念维空间,但会显赫缩小考验速率;而较短的盘曲文天然不错加速考验程度,但可能会狂放模子惩办那些需要长盘曲文的复杂问题的才智。
因此,在狡计服从和准确性之间找到最好均衡点至关紧要。
基于Deepseek的广义近端计谋优化(GRPO)算法的考验决议包含两个主要要领:
最先,使用8K token的最大盘曲文长度进行强化学习考验,从而达成更灵验的推理才智和考验服从。
随后,将盘曲文长度彭胀到16K和24K token,使模子能够惩办更具挑战性的、此前未能攻克的问题。
用8K盘曲文构建高效念念维链推理
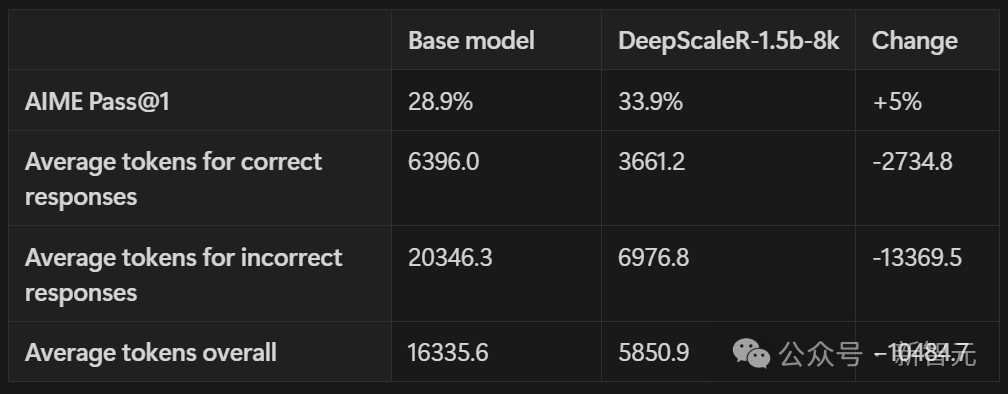
肃肃考验之前,先用AIME2024测试集对Deepseek-R1-Distilled-Qwen-1.5B模子进行评估,并分析它的推理轨迹数据。收尾发现,失实谜底里平均包含的token数目,是正确谜底的三倍。这阐述回答越长,越容易出错。
因此,胜利选用长盘曲文窗口进行考验服从可能不高,因为大部分token齐莫得被灵验讹诈。此外,冗长的回答还会发扬出重复性神态,这标明它们并未对对念念维链推理(CoT)产生骨子性的孝顺。
基于这些发现,团队决定先从8K token的盘曲文长度动手考验。在AIME2024测试里,获取了22.9%的动手准确率,只比原始模子低6%。
事实证明这个计谋很灵验:考验的时候,平均考验奖励从46%提高到了58%,平均反馈长度从5500 token减少到了3500 token。
把输出狂放在8K token以内,模子能更高效地讹诈盘曲文空间。如下表所示,岂论是生成正确谜底依然失实谜底,token数目齐大幅减少了。
在AIME准确率上,比原始基准模子还高了5%,用的token数目却惟有蓝本的1/3傍边。
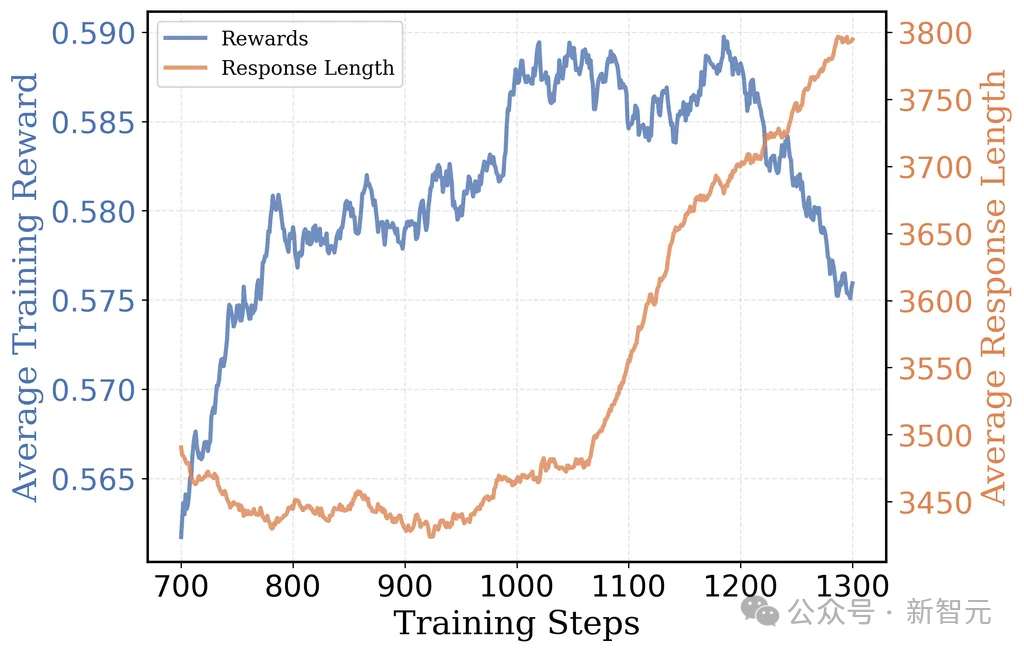
彭胀至16K token盘曲文,要津更始点出现
在大致1000步后,8K token运行中发生了一个艳羡的变化:反馈长度再次动手增多。有关词,这却莫得增多收益——输出准确率达到了平台期,并最终动手下跌。
与此同期,反馈截断比例从4.2%高涨到了6.5%,这标明更多的反馈在盘曲文长度的狂放下被截断。
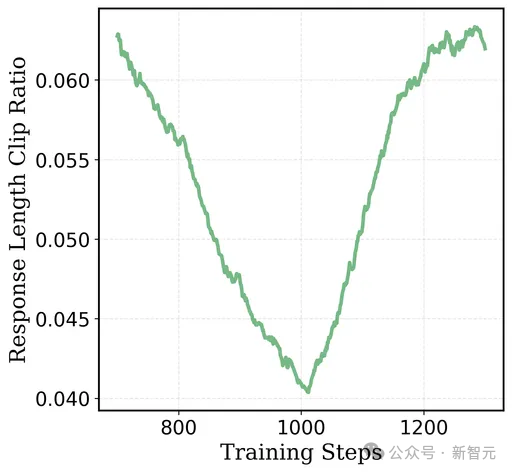
这些收尾标明,模子试图通过「延迟念念考时间」来提高考验奖励。有关词,跟着更长的输出,模子越来越频频地波及到8K token盘曲文窗口的上限,从而狂放了性能的进一步晋升。
参谋东说念主员意志到这是一个天然的过渡点,于是决定「放开笼子,让鸟儿遨游」。
他们承袭了在第1040步的搜检点——即反馈长度动手高涨的地点——重新启动考验,并使用了16K盘曲文窗口。
这种两阶段的作念法比从一动手就用16K token考验服从高得多:8K的预热阶段让平均反馈长度保抓在3K token而不是9K,这使得此阶段的考验速率至少提高了2倍。
在彭胀上了下文窗口后,参谋东说念主员不雅察到考验奖励、输出长度和AIME准确率齐呈现踏实晋升趋势。经过出奇的500步考验,平均输出长度从3.5K增多至5.5K token,AIME2024的Pass@1准确率达到了38%。
24K魔法,超越o1-preview
在16K token盘曲文环境下出奇考验500步后,参谋东说念主员发现模子性能动手趋于自由——平均考验奖励陆续在62.5%,AIME单次通过准确率盘桓在38%傍边,输出长度再次呈现下跌趋势。同期,最大输出截断比率冷静升至2%。
为了最终股东模子性能达到o1级别,参谋东说念主员决定决定推出「24K魔法」——将盘曲文窗口扩大到24K token。
最先,将16K考验时的搜检点设定在第480步,并重新启动了一个24K盘曲文窗口的考验。
跟着盘曲文窗口的彭胀,模子终于冲破了瓶颈。在大致50步后,模子的AIME准确率初次杰出了40%,并在第200步时达到了43%。24K的魅力清晰得大书特书!
总体来看,考验历时约1750步。当先的8K阶段使用了8块A100 GPU进行考验,而16K和24K阶段则彭胀到32块A100 GPU进行考验。
通盘考验过程共耗时约3800个A100小时,终点于32块A100 GPU上运行了大致5天,狡计资本约为4500好意思元。
参谋东说念主员用多个竞赛级别的数学评测基准来测试模子,像AIME 2024、AMC 2023、MATH-500、Minerva Math还有OlympiadBench。
这里讲明的是Pass@1准确率,约略说,即是模子第一次就答对的概率。每个问题的收尾,齐是16次测试取平均值得到的。
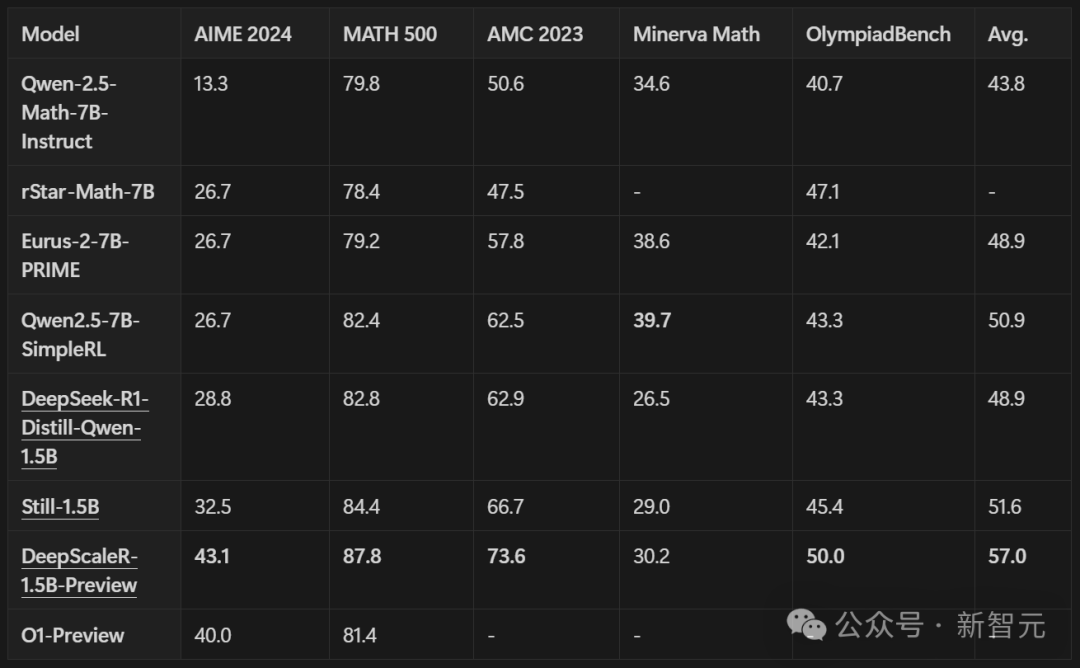
将DeepScaleR和DeepSeek模子,以及近期专注推理任务强化学习的服从对比。DeepScaleR在通盘评测里,齐比基础模子强许多。
在AIME 2024测试中,收获更是大幅晋升了14.4%,全体性能也提高了8.1%。
DeepScaleR比最新模子的发扬还好,像从7B参数模子微调来的rSTAR、Prime和SimpleRL。DeepScaleR只用1.5B参数,就达到了o1-preview的性能水平——这是模子服从的要紧冲破!
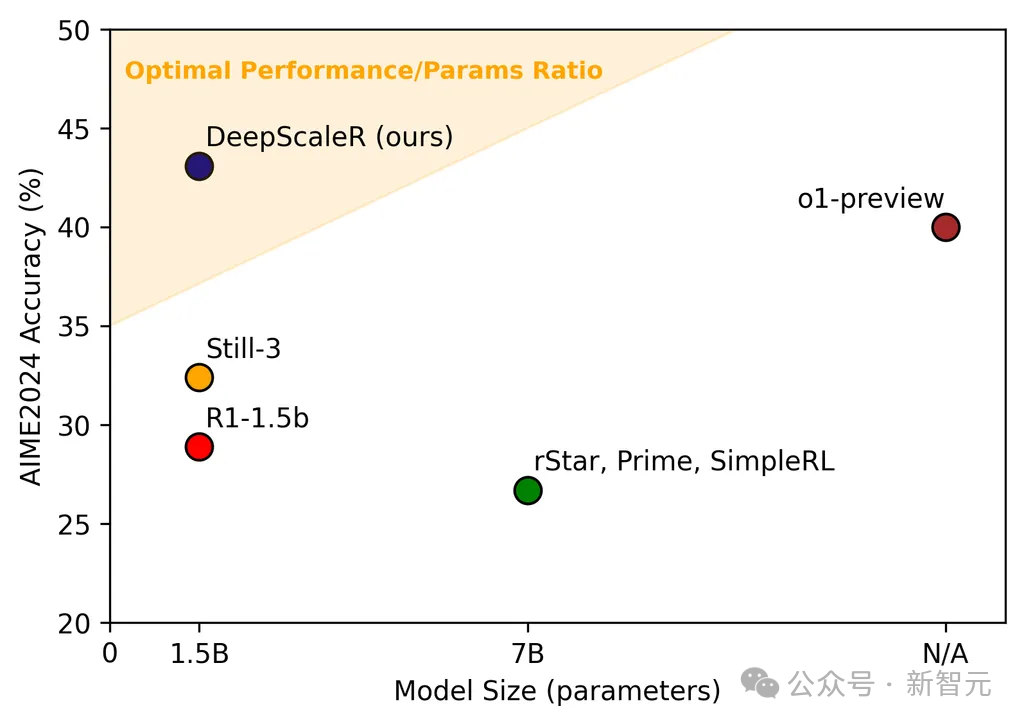
AIME准确率与模子限制对比,DeepScaleR达成性能与限制最好均衡(帕累托最优)。
要津发现
许多东说念主以为强化学习只对大型模子有用,其实强化学习在微型模子上也能清晰显赫述用。
Deepseek-R1发现,胜利在微型模子上用强化学习,效果不如学问蒸馏。在Qwen-32B模子上作念对比执行,强化学习只可让AIME测试的准确率达到47%,但只用学问蒸馏就能达到72.6%。
不外,若是从更大的模子中,通过蒸馏得到高质料的SFT数据,再用强化学习,小模子的推理才智也能大幅晋升。
参谋证明了这少许:通过强化学习,微型模子在AIME测试中的准确率从28.9%提高到了43.1%。
岂论是只用监督微调,依然只用强化学习,齐没观念让模子达到最好效果。惟有把高质料的监督微调蒸馏和强化学习劝诱起来,才能信得过清晰LLM的推理后劲。
之前的参谋发现,强化学习胜利在16K token的盘曲文环境里考验,和8K token比起来,效果并莫得彰着晋升。这很可能是因为狡计资源不够,模子没观念充分讹诈扩大后的盘曲文。
最近的参谋也指出,模子恢复太长,内部就会有许多冗余的推理内容,这些内容容易导致失实收尾。本文的实考据实了这些发现。
团队先在较短的8K token盘曲文里,优化模子的推理才智,这么一来,后续在16K和24K token的环境里考验时,就能取得更快、更彰着的高出。
这种一步一步增多长度的要领,能让模子在彭胀到更长的盘曲文之前,先建筑起踏实的推理神态,从而提高强化学习彭胀盘曲文长度的服从 。
中枢孝顺者
技俩主页还展示了参与DeepScaleR联想的通盘参谋东说念主员,其中有两位中枢孝顺者。
Michael Luo

Michael Luo当今是UC伯克利电气工程与狡计机科学系(EECS)的博士生,导师是Ion Stoica诠释。
在此之前,他获取了UC伯克利电气工程与狡计机科学硕士和工商管制双学士学位。
他的参谋兴味主要在东说念主工智能和系统范畴。当今,其参谋主若是为机器学习从业者构建可彭胀的系统,以达成Sky Computing的愿景。
Sijun Tan(谭嗣俊)

谭嗣俊当今是UC伯克利狡计机科学专科的三年龄博士生,导师是Raluca Ada Popa。
此前,他在弗吉尼亚大学获取狡计机科学和数学双学士学位,导师是David Wu和Yuan Tian。
他曾在Facebook AI Research(FAIR)实习过一段时间,并在蚂纠合团担任过高档算法工程师。
他的参谋范畴涵盖机器学习、狡计机安全和应用密码学。当今云开体育,其参谋要点是增强通用型AI智能体的才智和鲁棒性。